
Der Basic Track richtet sich an Gymnasiasten. In dem Datenanalyse-Wettbewerb der Cognitive Systems Lab (CSL) und Zentrum für angewandte Raumfahrttechnologie und Mikrogravitation (ZARM) der Universität Bremen messen sich Teilnehmende um Preisgelder 2.000 Euro und attraktive Sachpreise.
Hauptverantwortlicher
ZARM-Track
Technicher Unterstützer
Textpolitur
Supervisor
Finanzieller Unterstützer
Hui Liu (hui.liu@uni-bremen.de)
Ina Barwich und Benny Rievers
Yale Hartmann, Marvin Borsdorf und Dashanka de Silva
Elisa Brauße
Tanja Schultz und Heinz Brandt









Die ZARM-Challenge befasst sich mit dem Thema Exploration auf fremdem Himmelskörpern wie z.B. dem Mars; also wie erkunde ich einen Planeten? Man muss Informationen über die Umgebung sammeln, um sich beispielsweise sicher über die noch unbekannte Oberfläche navigieren zu können. Dies ist exakt so, wie auch bei echten Raumfahrtmissionen. Zur Bearbeitung der ZARM-Challenge erhalten alle Gruppen einen Legobaukasten der Spike Prime Serie. Aus diesem bauen sie einen Rover und programmieren ihn so, dass er eine Karte mit vier Hindernissen abfahren und kartographieren kann. Ziel ist, dass auch jemand, der die Karte nie gesehen hat, weiß, welche Hindernisse wo stehen und wie man sich um sie herumbewegen könnte. Neben dem Programmier-Code wird auch die technische Herangehensweise vom Expertenteam – bestehend aus Wissenschaftler:innen und Lehrkkräften – bewertet. Die Schulteams haben bis Ende Dezember 2023 Zeit, ihre Challenge möglichst gut und kreativ zu lösen.
Für die Challenge vom ZARM beschäftigt ihr euch mit den Themen Kartographie und Programmierung. Bearbeitet dazu die Aufgaben und orientiert euch an der Checkliste, um alle Schritte erfolgreich zu absolvieren.
1) Baut einen Roboter, der in der Lage ist selbstständig eine zu kartographierende Oberfläche zur Erfassung abzufahren. Was muss der Rover sehen? Wie bewegt er sich?
2) Programmiert diesen Roboter so, dass er in der Lage ist Daten seiner Umgebung aufzunehmen. Was braucht der Roboter für Daten? Wie erhalten ich diese Daten?
3) Erstellt aus den Daten des Roboters eine Visualisierung der Oberfläche. Wie kann eine solche Visualisierung aussehen? Versteht jemand die Karte, der die originale Umgebung nicht kennt? Enthält die Karte alle relevanten Informationen für jemanden, der nachher anhand dieser Karte im entsprechenden Gebiet navigieren will (über Land oder ggf. im Überflug).
Hinweis:
Die Karte gibt vor, wo die Objekte aufgestellt werden sollen und auch wie der Roboter hingestellt werden muss (Orientierung am Startknopf). Achtet vor Beginn darauf, dass hier alles richtig ist.
Welche Programme ihr zur Auswertung und Visualisierung nutzen sollt, findet ihr in der Checkliste.
Alle personenbezogenen Daten, die im Rahmen des Wettbewerbs erhoben werden (Name, E-Mail-Adresse und Hochschule bzw. Arbeitgeber der Teilnehmenden sowie IP-Adressen), werden nur innerhalb der Universität Bremen und nur für die Zwecke des Wettbewerbs verarbeitet und gespeichert. Die Namen der Gewinner:innen des Wettbewerbs werden bei Zustimmung veröffentlicht.
Die BBDC Basic unterteilt sich noch einmal in zwei Tracks: CSL und ZARM. BBDC Basic ist nur für Teilnehmende aus den sieben Bremer Gymnasien offen, die in diesem Jahr am „Nachwuchsförderung Bremer Wertpapierbörse“ Projekt teilnehmen. Wir können auch Uploads von Ergebnissen aus anderen Quellen erhalten, aber wir werden sie nicht in der endgültigen Rangliste berücksichtigen oder Preise an sie vergeben. Ebenso führt ein Verstoß gegen die Teilnahmebedingungen zum Ausschluss des Teams aus dem Wettbewerb.
Am Wettbewerb dürfen Teams mit bis zu 3 Mitgliedern teilnehmen (im Folgenden bezieht sich der Begriff „Team“ auch auf Einzelpersonen); jede Person darf nur in einem Team teilnehmen. Alle Teilnehmenden müssen der Vertraulichkeitserklärung bzgl. der zur Verfügung gestellten Daten zustimmen. Die Zustimmung wird während der Anmeldung zum Wettbewerb per Häkchen gegeben und digital gespeichert.
Ideenaustausch und Zusammenarbeit zwischen Teams ist erlaubt und erwünscht. Es ist auch gestattet verwandte Datenquellen zu nutzen, jedoch ist jedwede Nutzung der exakten Lösungsdaten (Daten, mit welchen die Einreichungen evaluiert werden), ohne Unterscheidung ob des Erhalts oder Einsatzes, untersagt.
Wir behalten uns vor, nur Lösungen zu akzeptieren, die zur Prüfung vollständig nachvollzogen werden können. Dies umfasst neben dem eigentlichen Programm auch die eingesetzten Bibliotheken und die zusätzlichen Datenquellen, die über die bereitgestellten Daten hinaus verwendet wurden. Nicht nachvollziehbare Einreichungen und Plagiatsverdachte werden durch eine unabhängige Fachjury überprüft, welche einen Ausschluss aussprechen kann.
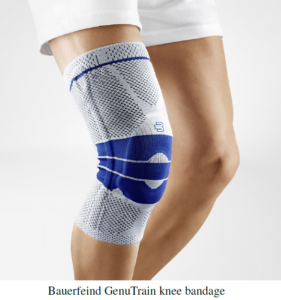
Die diesjährige Aufgabe ist die Erkennung menschlicher Bewegungen. Bitte trainieren Sie Ihren Computer, die sieben häufigsten Bewegungen des menschlichen Körpers anhand der Daten von mehreren in eine Kniebandage integrierten Sensoren automatisch zu erkennen
– geradeaus gehen (walk)
– sich beim Gehen nach links drehen (curve-left)
– sich beim Gehen nach rechts drehen (curve-right)
– sitzen (sit)
– stehen (stand)
– sich aus dem Stehen hinsetzen (stand-to-sit)
– aus dem Sitzen aufstehen (sit-to-stand)
Das heruntergeladene Paket besteht aus drei Teilen:
– einem Ordner mit dem Namen „Training“, der mehrere Dateien mit Big Data enthält. Die Dateinamen geben die Bedeutung der in der Datei enthaltenen Daten an (walk, curve-left, curve-right, sit, stand, stand-to-sit oder sit-to-stand) – in der KI nennen wir sie Bezeichnungen (labels), Annotationen, Referenzen oder Basiswahrheiten (ground-truth).
– einem Ordner namens „Testing“ enthält hundert Dateien mit den Namen „000.csv“ bis „099.csv“. Sie enthalten das gleiche Datenformat wie die Dateien im Ordner „Training“. Der Unterschied besteht darin, dass sie nicht beschriftet sind. Ihre Aufgabe besteht darin, ihnen Namen zu geben – in der KI-Sprache nennen wir sie Vorhersagen, Prädiktionen, Hypothesen oder Ergebnisse. Sie werden den Computer dazu bringen, jeder Datei automatisch eine Bezeichnung zu geben.
– einer einfachen Python-Routine, die in der Jupyter-Notebook-Umgebung läuft und Ihnen hilft, Daten bequem zu lesen, anzupassen, vorzuverarbeiten und zu visualisieren.
Dringendes Update (Ver. 2):
Jedes Team sollte EIN Konto registrieren. Bitte informieren Sie den Organisator nach der Anmeldung über Ihren Kontonamen per hui.liu@uni-bremen.de (um die Fairness des Wettbewerbs zu gewährleisten). Jedes Konto kann ab 1. November 2023 bis 17. Dezember einmal pro Woche Ergebnisse hochladen. Es sollte eine TEXTDATEI, beispielsweise mit dem Namen „result.txt“ sein, wobei jede Zeile einem Ergebnis entspricht. Diese Datei sieht zum Beispiel so aus:
walk
curve-left
curve-right
…
Die Datei hat 100 Zeilen. Das obige Beispiel zeigt, dass in den vom Computer erzeugten Ergebnissen 000.csv als walk angenommen wird, 001.csv wird als curve-left erkannt, und so weiter.
Eine Datei, die n (n<100) Zeilen enthält, wird nur für die ersten n Ergebnisse bewertet. Eine Datei, die >100 Zeilen enthält, wird nur für die ersten 100 Ergebnisse bewertet. Zeilen, die keine der sieben Bezeichnungen enthalten, werden als inkorrekt bewertet (z. B. walking oder stehen).
Nach dem Hochladen beginnt ein automatischer Prozess mit der Bewertung, indem jede Zeile mit einer vorher gespeicherten Grundwahrheit verglichen wird. Wenn es sich bei 000.csv beispielsweise tatsächlich um einen walk handelt, wird dem Ergebnis des obigen Beispiels ein Punkt hinzugefügt. Es gibt insgesamt einhundert Testing-Dateien, und wenn sie alle richtig sind, erhält man eine Punktzahl von 0, also 0% Fehlerquote. Bei 25 falschen Erkennungen beträgt die Punktzahl 0,25, also 25 % Fehlerquote. Die Rangliste wird nach jedem Hochladen eines neuen Ergebnisses in der Reihenfolge der höchsten bis niedrigsten Fehlerquote erstellt und automatisch aktualisiert.
Laden Sie außerdem gleichzeitig Ihren Quellcode (z. B. eine .ipynb-Datei oder eine .py-Datei) hoch und senden Sie Ihren Quellcode am Ende des Wettbewerbs an den Veranstalter.
Obwohl alle Gymnasiast:innen, die an diesem Wettbewerb teilnehmen, an der Vorprogrammierungsschulung teilgenommen haben und alle für die Teilnahme erforderlichen Details verstanden haben, stellen wir hier dennoch einige Details bereit.
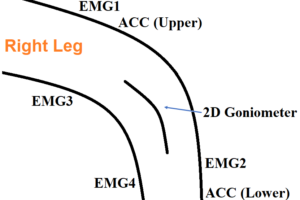
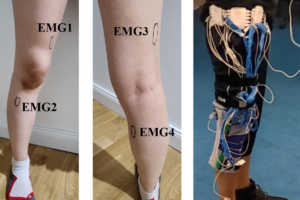
Dieses Mal haben wir insgesamt 12 Sensorkanäle verwendet, in der Reihenfolge:
– EMG-1 (EMG: Elektromyographie)
– EMG-2
– EMG-3
– EMG-4
– ACC-O-1 (ACC: Beschleunigung; O: Oberschenkel)
– ACC-O-2
– ACC-O-3
– Gonio-1 (Gonio: Goniometer)
– ACC-U-1 (U: Unterschenkel)
– ACC-U-2
– ACC-U-3
– Gonio-2
Das Bild unten zeigt die Position dieser Sensoren.
Comma-Separated Values. Es handelt sich im Wesentlichen immer noch um eine TXT-Datei (Textdokument), in der die Werte in jeder Zeile durch Kommas getrennt werden. Sie können einen beliebigen Texteditor (z. B. Notepad, Word usw.) unter jedem Betriebssystem verwenden, um die Datei zur Ansicht zu öffnen, oder Sie können Excel verwenden, um sie zu öffnen und als Tabelle anzuzeigen. Das Auslesen der Daten aus der CSV-Datei und das Speichern in Python-Parametern erledigt die zugehörige Routine bereits für Sie.
Da die Abtastrate 1000 Hz beträgt, erzeugt jeder Kanal jede Sekunde 1000 Datenabtastwerte. Zur Vereinfachung der Speicherung und des Öffnens sind die Daten der 12 Kanäle an eines Abtastpunkts als horizontale Zeilen in der Datei angeordnet, z. B. die ersten beiden Zeilen von walk_001.csv:
32938,32717,32644,32880,33112, …, 33802,30832
32900,33625,32673,32849,33112, …, 33802,30832
Das bedeutet, dass bei der ersten Probenahme der Wert von EMG-1 32938 beträgt, der Wert von EMG-2 32717, …, der Wert von Gonio-2 30832. Nach einer Millisekunde, während der zweiten Abtastung, beträgt der Wert von EMG-1 32900, der Wert von EMG-2 33625, ….
Da wir eine bequemere Verarbeitung von Daten mit künstlicher Intelligenz erwarten, hat Ihnen die Routine dabei geholfen, solche Datenstrukturen zu transponieren. Nach der Transposition werden die Daten jedes Kanals in die gleiche Liste integriert.
„Die Challenge „Exploration auf fremden Himmelskörper“ des ZARM hat uns viele Kopfschmerzen, aber auch viel Spaß bereitet. […] doch sind wir froh über die Dinge die wir in den Letzten Monaten durch diese Challenge mitgenommen und gelernt haben. […] Wir haben jetzt einen kleinen Einblick in eines der möglichen Felder des ZARM bekommen und sind erstaunt wie viel Arbeit hinter einem kleinem LEGO Roboter steckt und wieviel dann wohl hinter einem richtigem Marsroboter stecken könnte. Vielen dank an das ZARM für die Möglichkeit der Teilnahme an dieser Challenge, welche uns die Letzten Monate begleitet hat“
(Team die Kleisers – dritter Platz)